
In den letzten beiden Artikeln habe ich gezeigt, wie Frontend und Backend von Webanwendungen mithilfe von JSON-LD entkoppelt werden können. Dank JSON-LD sind weder die genauen JSON-Bezeichner noch spezifische "API-Endpunkte" im Backend relevant. Bei JSON-LD kommt es nicht mehr auf die konkrete Struktur und Syntax der Daten an, sondern auf die diesen inhärente Semantik. Dies liegt daran, dass JSON-LD eben kein spezifisches Datenformat ist, sondern lediglich eine JSON-Serialisierung von Linked Data . Um die Vorteile von JSON-LD zu verstehen, ist ein Blick auf die Eigenschaften von Linked Data hilfreich.
Bisherige Artikel
- Schmerzloser Datenaustausch: Mit JSON-LD Backend und Frontend entkoppeln
- Verlinkte Daten statt hart-kodierter Endpunkte
- Semantische Fakten statt fester Baumstruktur
Linked Data
Nehmen wir den Datensatz aus dem letzten Artikel als Beispiel:
1{ 2 "@context": { 3 "@vocab": "https://schema.org/", 4 "@base": "https://api.example/", 5 "firstname": "givenName", 6 "lastname": "familyName", 7 "street": "streetAddress", 8 "id": "@id" 9 }, 10 "id": "persons/42", 11 "firstname": "John", 12 "lastname": "Doe", 13 "address": { 14 "id": "addresses/1337", 15 "street": "Mainstreet 23" 16 } 17}
Ungeachtet der konkreten JSON-Struktur handelt es sich bei diesem Datensatz um zwei Ressourcen und deren Beziehungen. Die Daten lassen sich genauso gut tabellarisch darstellen:
| Subjekt | Prädikat | Objekt |
|---|---|---|
| https://api.example/persons/42 | https://schema.org/givenName | John |
| https://api.example/persons/42 | https://schema.org/familyName | Doe |
| https://api.example/persons/42 | https://schema.org/address | https://api.example/addresses/1337 |
| https://api.example/addresses/1337 | https://schema.org/streetAddress | Mainstreet 23 |
Wir haben hier eine Sammlung von Fakten, die Aussagen über eine Ressource (Subjekt) treffen. Die Ressourcen sind eindeutig über IRI s identifiziert. Ebenso ist die Art der Aussage (Prädikat) durch Verwendung von IRIs semantisch eindeutig. Als Objekt einer Aussage können primitive Datentypen verwendet werden, wie z. B. die Zeichenkette "John" als givenName. Durch Verwendung von IRIs als Objekt können wir auf andere Ressourcen verweisen, so wie dies bei der Adresse der Fall ist. Da es sich bei einer IRI um eine global eindeutige ID handelt, können sogar Ressourcen über APIs hinweg miteinander verlinkt werden. Daher kommt die Bezeichnung "Linked Data". Bei HTML nutzen wir dieses Prinzip ganz selbstverständlich, in strukturierten Daten fehlen solche Links leider viel zu oft.
Über die sogenannten "Daten-Tripel" aus Subjekt, Prädikat und Objekt lassen sich beliebige Fakten formulieren. Bei diesem Datenmodell handelt es sich um das "Resource Description Framework" (RDF) . RDF ist unabhängig von einer bestimmten Serialisierung, JSON-LD ist nur eine davon. Darüber hinaus gibt es zum Beispiel RDF-XML, Notation3 oder Turtle. RDF ist im akademischen Umfeld beliebt, jedoch nie in der alltäglichen Praxis von Webentwickler*innen angekommen, da die meisten Serialisierungen ungleich komplizierter zu handhaben sind als JSON.
Dies ändert sich mit JSON-LD grundlegend, da wir die Vorteile von einfach verwendbarem JSON und der starken Semantik von RDF vereinen. Egal in welcher Struktur und mit welchen Bezeichnern ein Backend Daten ans Frontend sendet: Es handelt sich dem Wesen nach stets um "Daten-Tripel", die wir in ein uns genehmes Format serialisieren können. Dies reicht von der simplen Änderung von Bezeichnern bis hin zur Umstrukturierung ganzer JSON-Bäume.
JSON-LD ermöglicht es, die Semantik der Daten losgelöst von der Serialisierung des Backends zu betrachten und die Daten in einer neuen Form zu serialisieren. Das Frontend kann dazu die Form wählen, die es für am besten geeignet hält. Im Folgenden zeige ich einige Beispiele, wie die obigen Daten im Frontend serialisiert werden können.
Eigene JSON-Bezeichner und vollständige IRIs
Das Frontend-Team entscheidet sich, die Struktur des Backends beizubehalten, aber eigene JSON-Bezeichner zu wählen und über vollständige IRIs zu verlinken. Auf die Addresse kann dann leicht über person.address zugegriffen werden. Weitere Daten werden von person.address.iri geladen.
1{ 2 "@context": { 3 "@vocab": "https://schema.org/", 4 "first": "givenName", 5 "last": "familyName", 6 "location": "streetAddress", 7 "iri": "@id" 8 }, 9 "iri": "https://api.example/persons/42", 10 "address": { 11 "iri": "https://api.example/addresses/1337", 12 "location": "Mainstreet 23" 13 }, 14 "last": "Doe", 15 "first": "John" 16}
Flache Liste von Ressourcen
Das Frontend-Team entscheidet sich, alle Ressourcen in einer flachen Array-Liste vorzuhalten. Die Person enthält lediglich eine Referenz auf die IRI der Adresse. In dieser Form sind alle Ressourcen leicht über ihre ID zu ermitteln, ohne eine Hierarchie von Verschachtelungen durchgehen zu müssen. z.B.
1data["@graph"].find((it) => it.id === "addresses/1337");
1{ 2 "@context": { 3 "@vocab": "https://schema.org/", 4 "@base": "https://api.example/", 5 "id": "@id" 6 }, 7 "@graph": [ 8 { 9 "id": "addresses/1337", 10 "streetAddress": "Mainstreet 23" 11 }, 12 { 13 "id": "persons/42", 14 "address": { 15 "id": "addresses/1337" 16 }, 17 "familyName": "Doe", 18 "givenName": "John" 19 } 20 ] 21}
Umkehren der Verschachtelung
Das Frontend-Team möchte eine andere Form der Verschachtelung. Hier kann das Frontend nun über address.resident auf die Person zugreifen, statt umgekehrt über person.address die Adresse einer Person zu ermitteln. Im Kontext wird dazu mit dem Schlüsselwort @reverse angegeben, dass es sich bei resident um die Beziehung https://schema.org/address handelt, jedoch Subjekt und Objekt vertauscht sind.
1{ 2 "@context": { 3 "@vocab": "https://schema.org/", 4 "resident": { 5 "@reverse": "address" 6 }, 7 "uri": "@id" 8 }, 9 "uri": "https://api.example/addresses/1337", 10 "resident": { 11 "uri": "https://api.example/persons/42", 12 "givenName": "Doe", 13 "familyName": "John" 14 }, 15 "streetAddress": "Mainstreet 23" 16}
Datenhaltung im Frontend
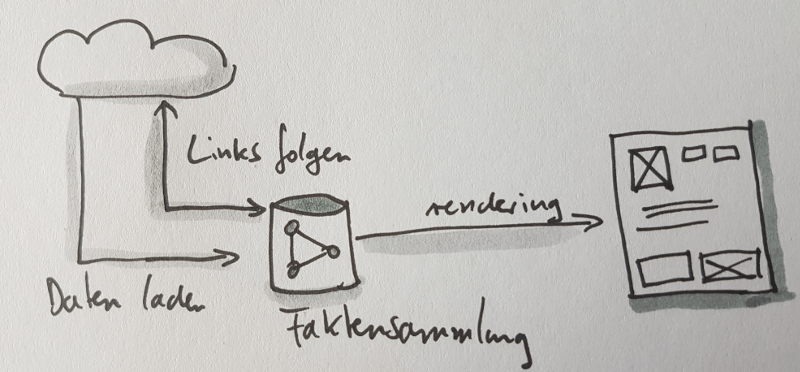
Da das Frontend letzlich immer "Daten-Tripel" vom Backend lädt, kann es die Sammlung dieser Tripel im Speicher vorhalten und mit jeder Antwort vom Backend um weitere Fakten anreichern. Zunächst wird z. B. die Person geladen, dann deren Adresse, dann weitere verlinkte Daten wie z. B. Geoinformationen über den Wohnort. Die Faktensammlung auf Frontend-Seite wächst, wird in eine geeignete Form gebracht und dann von Frontend-Komponenten dargestellt.
Fazit
All dies ist möglich, weil es bei JSON-LD eben nicht auf die Syntax und Struktur eines JSON-Objekts ankommt, sondern die dahinterliegende Semantik entscheidend ist. Die wesentliche Frage lautet, welche Daten-Tripel ausgetauscht werden. In welcher Form diese serialisiert werden, bleibt den Teams selbst überlassen und kann unabhängig voneinander geändert werden.
Ausblick
In meinen Artikeln habe ich mich auf die Verarbeitung von Backend-Daten im Frontend fokussiert. Natürlich gilt das Gesagte aber auch für den umgekehrten Weg: Daten, die das Frontend zurück ans Backend sendet, sind mit JSON-LD ebenso unabhängig von einer konkreten Struktur. Das Backend kann darauf den eigenen Kontext anwenden und ist vor Änderungen auf Frontend-Seite gefeit. Das Gleiche gilt auch für den Datenaustausch zwischen Backend-Services. JSON-LD eignet sich zum Beispiel hervorragend, um den Datenaustausch zwischen Microservices zu realisieren oder Drittanbieter-APIs zu integrieren.
JSON-LD bietet mehr Funktionalität, als ich in meinen Artikeln unterbringen konnte. Abschließend daher noch einige Links für alle, die sich weiter mit dem Thema befassen wollen. Ich freue mich auch über Feedback in den Kommentaren.
War dieser Beitrag hilfreich?



Weitere Beiträge
von Angelo Veltens
Dein Job bei codecentric?
Jobs
Agile Developer und Consultant (w/d/m)

Alle Standorte
Weitere Artikel in diesem Themenbereich
Entdecke spannende weiterführende Themen und lass dich von der codecentric Welt inspirieren.
Blog-Autor*in
Angelo Veltens
Software Developer & Consultant
Du hast noch Fragen zu diesem Thema? Dann sprich mich einfach an.
Du hast noch Fragen zu diesem Thema? Dann sprich mich einfach an.